本文的试验环境为CentOS 7.3,Kubernetes集群为1.11.2,安装步骤参见kubeadm安装kubernetes V1.11.1 集群 。想要了解更多 Kubernetes 相关知识,可以阅读 Kubernetes 系列学习文章 。
1. 环境准备 Elasticsearch运行时要求vm.max_map_count内核参数必须大于262144,因此开始之前需要确保这个参数正常调整过。
1 $ sysctl -w vm.max_map_count=262144
也可以在ES的的编排文件中增加一个initContainer来修改内核参数,但这要求kublet启动的时候必须添加了--allow-privileged参数,但是一般生产中不会给加这个参数,因此最好在系统供给的时候要求这个参数修改完成。
ES的配置方式
使用Cluster Update Setting API动态修改配置
使用配置文件的方式,配置文件默认在 config 文件夹下,具体位置取决于安装方式。
elasticsearch.yml 配置Elasticsearch
jvm.options 配置ES JVM参数
log4j.properties 配置ES logging参数
使用Prompt方式在启动时输入node.name: ${HOSTNAME}
ES的节点 ES的节点Node 可以分为几种角色:
Master-eligible node,是指有资格被选为Master节点的Node,可以统称为Master节点。设置node.master: true
Data node,存储数据的节点,设置方式为node.data: true。
Ingest node,进行数据处理的节点,设置方式为node.ingest: true。
Trible node,为了做集群整合用的。
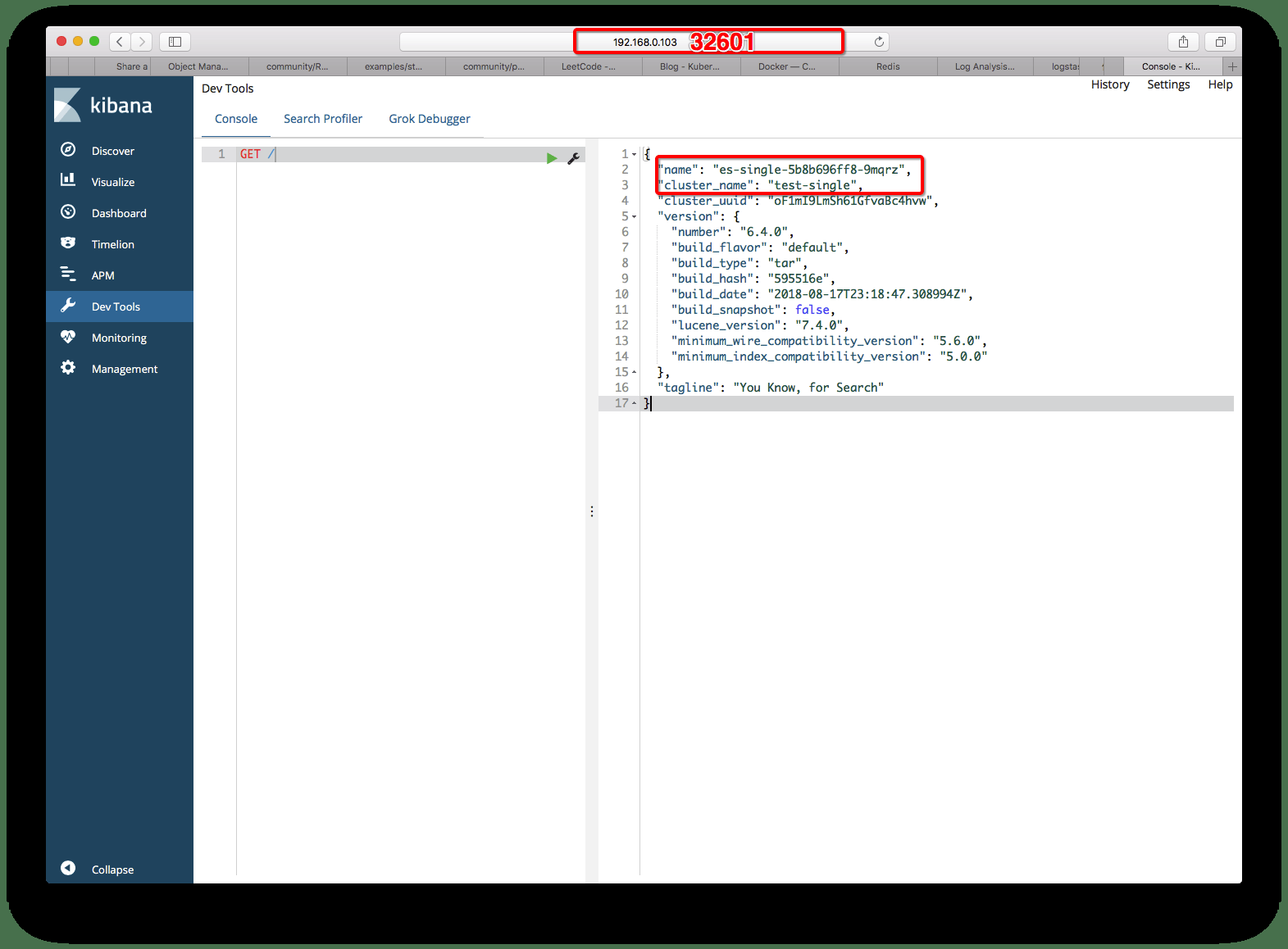
2. 单实例方式部署ELK 单实例部署ELK的方法非常简单,可以参考我Github上的elk-single.yaml 文件,整体就是创建一个ES的部署,创建一个Kibana的部署,创建一个ES的Headless服务,创建一个Kiana的NodePort服务,本地通过节点的NodePort访问Kibana。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 [root@devops-101 ~] [root@devops-101 ~] deployment.apps/kb-single created service/kb-single-svc unchanged deployment.apps/es-single created service/es-single-nodeport unchanged service/es-single unchanged [root@devops-101 ~] NAME READY STATUS RESTARTS AGE pod/es-single-5b8b696ff8-9mqrz 1/1 Running 0 26s pod/kb-single-69d6d9c744-sxzw9 1/1 Running 0 26s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/es-single ClusterIP None <none> 9200/TCP,9300/TCP 19m service/es-single-nodeport NodePort 172.17.197.237 <none> 9200:31200/TCP,9300:31300/TCP 13h service/kb-single-svc NodePort 172.17.27.11 <none> 5601:32601/TCP 19m service/kubernetes ClusterIP 172.17.0.1 <none> 443/TCP 14d NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE deployment.apps/es-single 1 1 1 1 26s deployment.apps/kb-single 1 1 1 1 26s NAME DESIRED CURRENT READY AGE replicaset.apps/es-single-5b8b696ff8 1 1 1 26s replicaset.apps/kb-single-69d6d9c744 1 1 1 26s
可以看看效果如下:
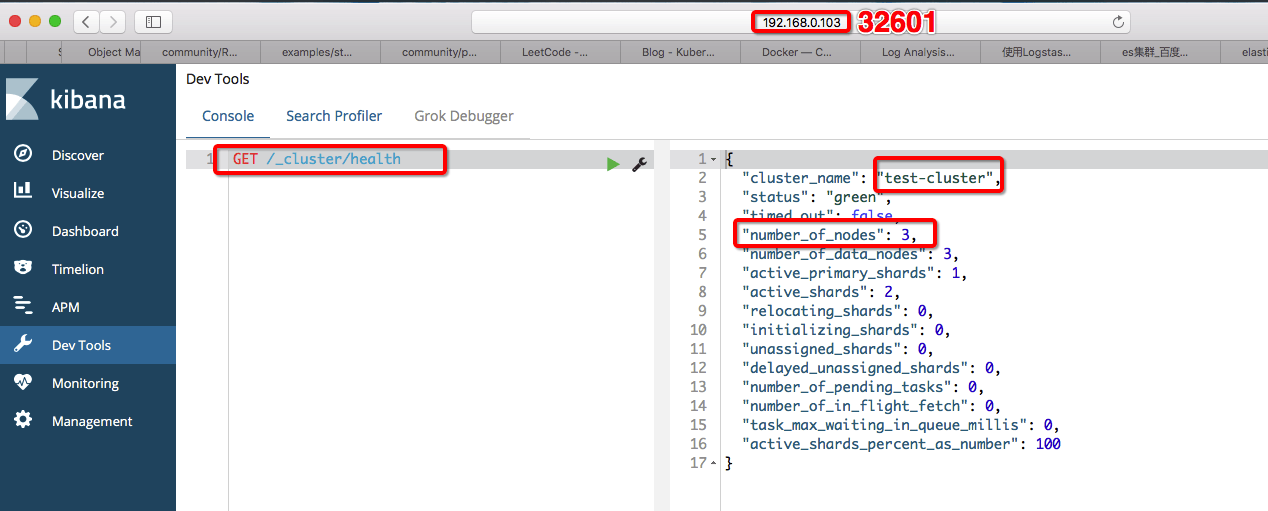
3. 集群部署ELK 3.1 不区分集群中的节点角色 1 2 3 4 5 6 7 [root@devops-101 ~] [root@devops-101 ~] deployment.apps/kb-single created service/kb-single-svc created statefulset.apps/es-cluster created service/es-cluster-nodeport created service/es-cluster created
效果如下
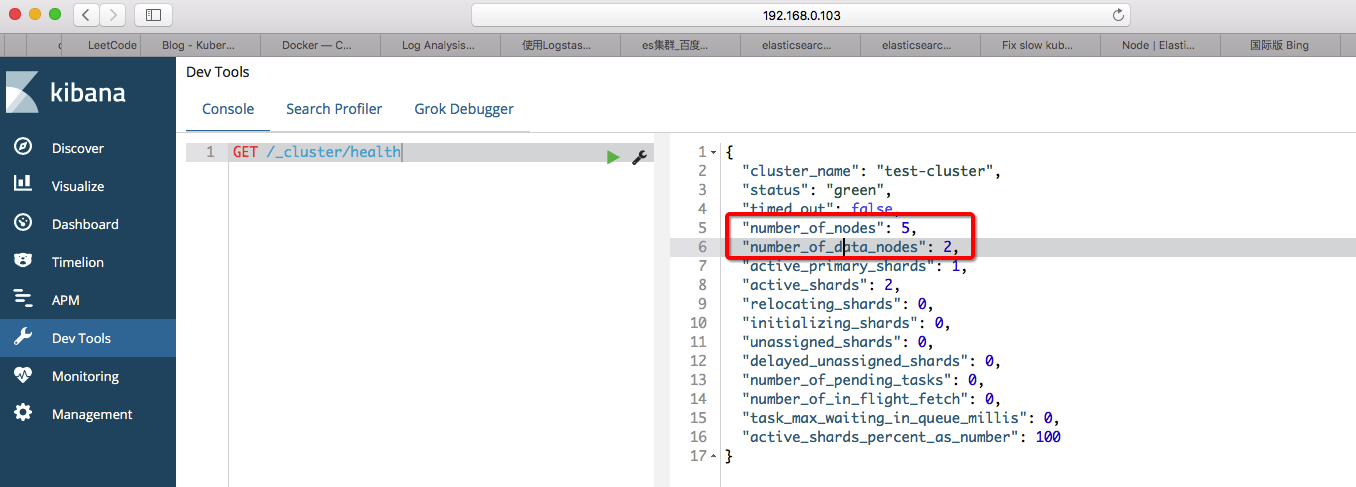
3.2 区分集群中节点角色 如果需要区分节点的角色,就需要建立两个StatefulSet部署,一个是Master集群,一个是Data集群。Data集群的存储我这里为了简单使用了emptyDir,可以使用localStorage或者hostPath,关于存储的介绍,可以参考Kubernetes存储系统介绍 。这样就可以避免Data节点在本机重启时发生数据丢失而重建索引,但是如果发生迁移的话,如果想保留数据,只能采用共享存储的方案了。具体的编排文件在这里elk-cluster-with-role
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 [root@devops-101 ~] [root@devops-101 ~] deployment.apps/kb-single created service/kb-single-svc created statefulset.apps/es-cluster created statefulset.apps/es-cluster-data created service/es-cluster-nodeport created service/es-cluster created [root@devops-101 ~] NAME READY STATUS RESTARTS AGE pod/es-cluster-0 1/1 Running 0 13s pod/es-cluster-1 0/1 ContainerCreating 0 2s pod/es-cluster-data-0 1/1 Running 0 13s pod/es-cluster-data-1 0/1 ContainerCreating 0 2s pod/kb-single-5848f5f967-w8hwq 1/1 Running 0 14s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/es-cluster ClusterIP None <none> 9200/TCP,9300/TCP 13s service/es-cluster-nodeport NodePort 172.17.207.135 <none> 9200:31200/TCP,9300:31300/TCP 13s service/kb-single-svc NodePort 172.17.8.137 <none> 5601:32601/TCP 14s service/kubernetes ClusterIP 172.17.0.1 <none> 443/TCP 16d NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE deployment.apps/kb-single 1 1 1 1 14s NAME DESIRED CURRENT READY AGE replicaset.apps/kb-single-5848f5f967 1 1 1 14s NAME DESIRED CURRENT AGE statefulset.apps/es-cluster 3 2 14s statefulset.apps/es-cluster-data 2 2 13s
效果如下
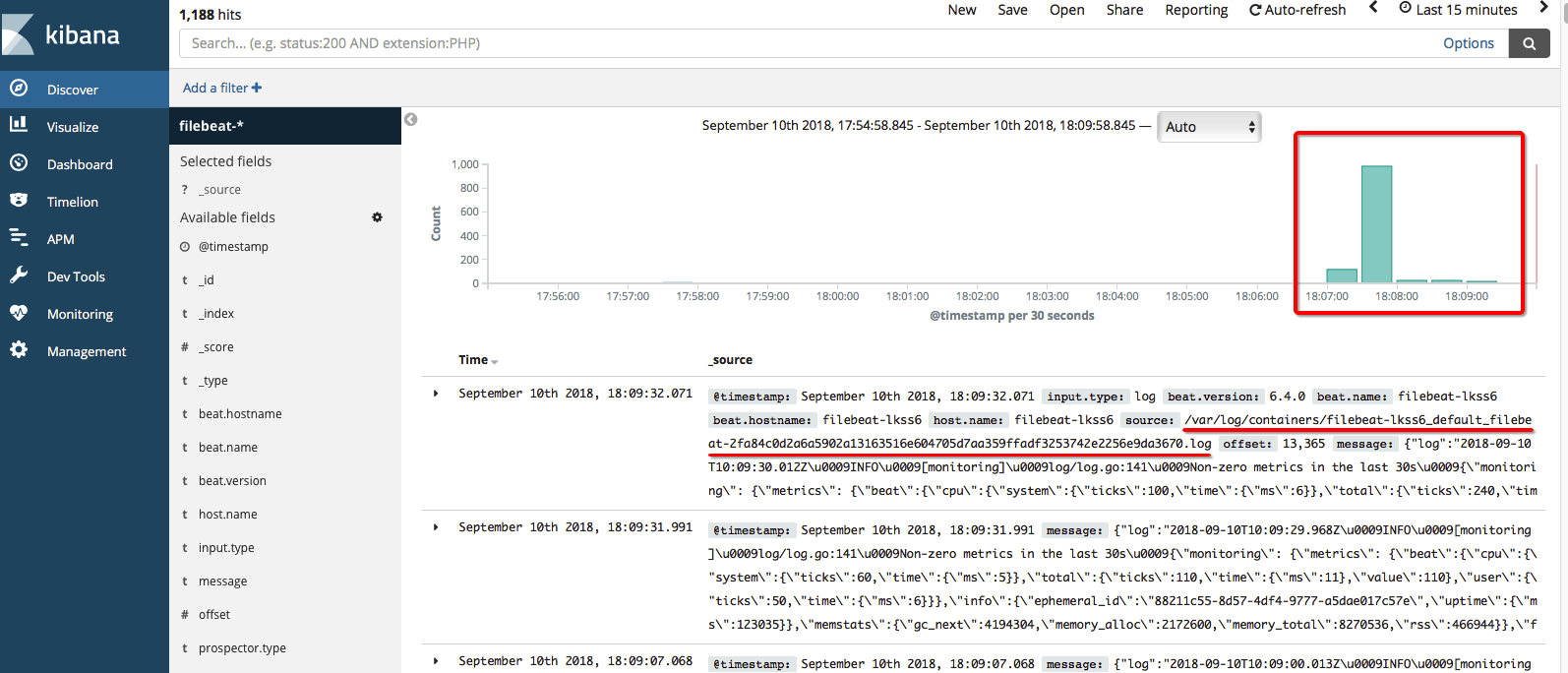
4. 使用Filebeat监控收集容器日志 使用Logstash,可以监测具有一定命名规律的日志文件,但是对于容器日志,很多文件名都是没有规律的,这种情况比较适合使用Filebeat来对日志目录进行监测,发现有更新的日志后上送到Logstash处理或者直接送入到ES中。/var/log/containers目录下创建软链接,这里我遇到了两个小问题,第一个就是当时挂载hostPath的时候没有挂载软链接的目的文件夹,导致在容器中能看到软链接,但是找不到对应的文件;第二个问题是宿主机上这些日志权限都是root,而Pod默认用filebeat用户启动的应用,因此要单独设置下。
具体的编排文件可以参考我的Github主页,提供了Deployment 方式的编排和DaemonSet 方式的编排。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 kind: List apiVersion: v1 items: - apiVersion: v1 kind: ConfigMap metadata: name: filebeat-config labels: k8s-app: filebeat kubernetes.io/cluster-service: "true" app: filebeat-config data: filebeat.yml: | processors: - add_cloud_metadata: filebeat.modules: - module: system filebeat.inputs: - type: log paths: - /var/log/containers/*.log symlinks: true # json.message_key: log # json.keys_under_root: true output.elasticsearch: hosts: ['es-single:9200'] logging.level: info - apiVersion: extensions/v1beta1 kind: DaemonSet metadata: name: filebeat labels: k8s-app: filebeat kubernetes.io/cluster-service: "true" spec: template: metadata: name: filebeat labels: app: filebeat k8s-app: filebeat kubernetes.io/cluster-service: "true" spec: containers: - image: docker.elastic.co/beats/filebeat:6.4.0 name: filebeat args: [ "-c" , "/home/filebeat-config/filebeat.yml" , "-e" , ] securityContext: runAsUser: 0 volumeMounts: - name: filebeat-storage mountPath: /var/log/containers - name: varlogpods mountPath: /var/log/pods - name: varlibdockercontainers mountPath: /var/lib/docker/containers - name: "filebeat-volume" mountPath: "/home/filebeat-config" nodeSelector: role: front volumes: - name: filebeat-storage hostPath: path: /var/log/containers - name: varlogpods hostPath: path: /var/log/pods - name: varlibdockercontainers hostPath: path: /var/lib/docker/containers - name: filebeat-volume configMap: name: filebeat-config
参考资料:
Elasticsearch cluster on top of Kubernetes made easy Install Elasticseaerch with Docker Docker Elasticsearch Running Kibana on Docker Configuring Elasticsearch Elasticsearch Node Loggin Using Elasticsearch and kibana Configuring Logstash for Docker Running Filebeat on Docker Filebeat中文指南 Add experimental symlink support